Customizing AI Responses with Llama Index: A Case Study in Data-Specific Interaction


Table of contents


No headings in the article.
Introduction:
In the realm of AI-driven applications, ensuring that an AI model responds solely based on a specific dataset can be a pivotal requirement. This blog takes you through a journey of customizing a model to limit its responses to a predefined dataset, a task especially relevant in scenarios where external knowledge sources are either unnecessary or potentially misleading.
Understanding the Problem:
The core challenge was to make an AI model, particularly a Flask-based application utilizing OpenAI's models, respond strictly based on our own indexed documents, without drawing upon its extensive external knowledge base.
Initial Setup:
\=> Data Preparation & Indexing: We began by organizing our documents using Llama Index, a powerful tool for managing and indexing data. This step was crucial to ensure efficient retrieval and processing of documents.

\=> Embedding Generation with OpenAI: To deepen our model's understanding, we generated vector embeddings for each document using OpenAI's embedding model. These embeddings capture the essence of each document in a vector form, enabling sophisticated comparison techniques.
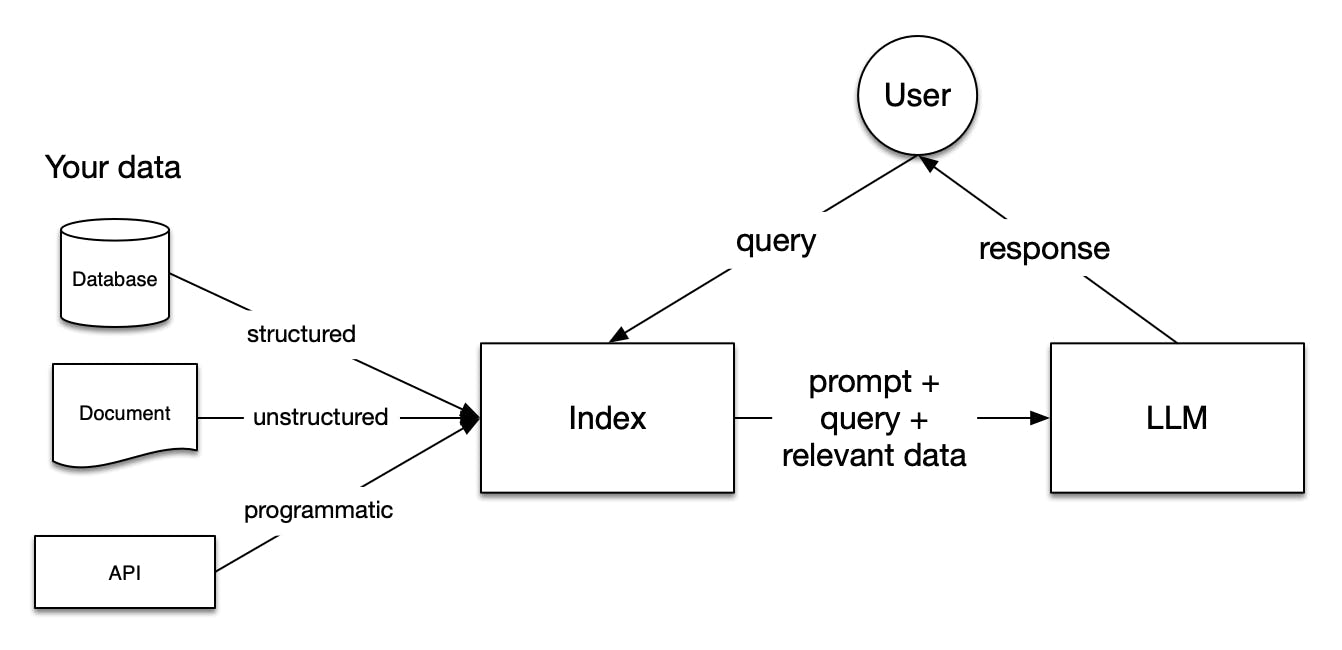
\=>Developing a Similarity Threshold Mechanism: To align user queries with relevant documents, we established a similarity threshold. By calculating cosine similarity between query and document embeddings, we could identify documents that closely matched the query context.
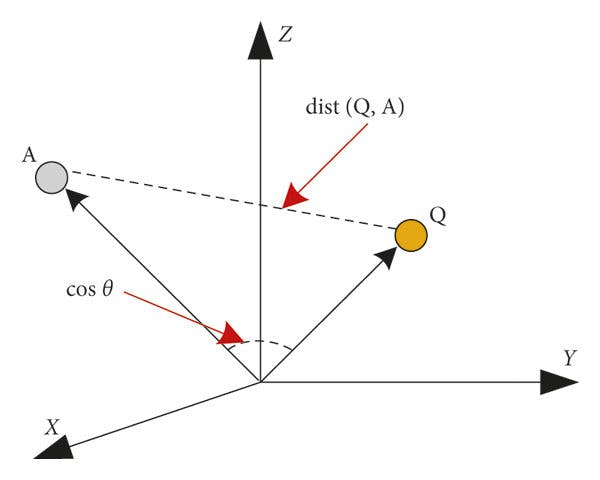
\=> Query Processing & Response Generation: When a user query was received, its embedding was compared against our indexed documents. If a document’s similarity exceeded our threshold, it informed the response; otherwise, a default response indicated the absence of relevant data.
Conclusion:
This process exemplifies the versatility and customization capabilities of AI models. By tailoring the response generation mechanism of an AI model to our specific dataset, we achieved a high degree of control over the information the model provided, making it suitable for specialized applications where accuracy and relevance of information are critical.